Adatbázis Sémák

A tesztkörnyezeten alkalmazásverziónként külön adatbázis sémákat tarthatunk karban.
Ennek előnye, hogy amennyiben szükséges telepíteni az éppen fejlesztés alatt álló verziótól korábbi verziójú alkalmazást (pl.: hotfix verzió visszatesztelése miatt), akkor az megtehető a séma eldobása nélkül.
Ehhez szükséges, hogy adott verzió release-ét követően készítsük el az új verzióhoz tartozó adatbázis sémát.
Azt, hogy melyik alkalmazás verziót melyik adatbázis sémával együtt kell elindítani a deploy-to-aws job automatikusan átadja
környezeti változóként az AWS tesztkörnyezetnek. Így csak arra kell ügyelnünk, hogy az új alkalmazás verzió telepítése előtt már legyen létrehozva a hozzá tartozó adatbázis séma.
1. Adatbázis séma létrehozása
1.1 Elnevezési konvenció
Az adatbázis sémák elnevezésekor az alábbi formátumot kell követni:
Ahol a${major-version-number}, ${minor-version-number} és ${patch-version-number} placeholderek helyére értelemszerűen az alkalmazás megfelelő MAJOR, MINOR és PATCH verziószámait kell behelyettesíteni.
Például
- Ha az alkalmazás verzió
1.0.0-SNAPSHOTakkor a hozzá tartozó adatbázis séma neve a következő legyen:V1_0_0. - Ha az alkalmazás verzió
2.1.0akkor a hozzá tartozó adatbázis séma neve a következő legyen:V2_1_0.
1.2 Új üres séma létrehozása
Amennyiben egy új üres sémára van szükségünk, használjuk az adatbáziskezelő szoftverek beépített séma létrehozó funkcióját.
Például IntelliJ-ben: Az adatbázishoz kapcsolódva jobb egérgombbal kattintsunk az adatbázis nevére pl.: postgres, majd a megjelenő menüből válasszuk ki a New → Schema menüpontot:

2. Adatbázis séma másolása
2.1 PostgreSQL
- SSH-n keresztül csatlakozzunk az AWS Instance-hoz.
- Lépjünk be az adatbázist futtató container-be az alábbi paranccsal:
-
Váltsunk a
postgresfelhasználóra: -
Készítsünk backup fájlt a másolandó sémáról:
- Nyissuk meg a PostgreSQL terminált:
- A terminálban adjuk ki az alábbi parancsot:
- Lépjünk ki a terminálból:
-
Végül az alábbi paranccsal töltsük vissza az eredeti sémát a backup-ból:
- A
${másolandó-séma-neve}placeholder helyére értelemszerűen a másolni kívánt séma nevét kell behelyettesíteni. - Az
${új-séma-neve}placeholder helyére értelemszerűen az új séma nevét kell behelyettesíteni.
- A
2.2 IBM Db2
- Amennyiben létezik az
ERROR_SCHEMA.ERROR_TABLE, azt dobjuk el: -
A következő utasításokkal tudjuk elvégezni a másolást:
CREATE OR REPLACE VARIABLE ${másolandó-séma-neve}.ERROR_SCHEMA_NAME VARCHAR(128) DEFAULT 'ERROR_SCHEMA'; CREATE OR REPLACE VARIABLE ${másolandó-séma-neve}.ERROR_TABLE_NAME VARCHAR(128) DEFAULT 'ERROR_TABLE'; CALL SYSPROC.ADMIN_COPY_SCHEMA('${másolandó-séma-neve}', '${új-séma-neve}', 'COPY', NULL, NULL, NULL, ${másolandó-séma-neve}.ERROR_SCHEMA_NAME, ${másolandó-séma-neve}.ERROR_TABLE_NAME);- A
${másolandó-séma-neve}placeholder helyére értelemszerűen a másolni kívánt séma nevét kell behelyettesíteni. - Az
${új-séma-neve}placeholder helyére értelemszerűen az új séma nevét kell behelyettesíteni.
- A
2.3 Egyéb
Amennyiben a projekten a fentiektől különböző adatbázist használunk, úgy nézzünk utána, hogy az adott adatbázis esetén milyen lépésekkel lehet a sémát másolni, illetve hogyan lehet specifikus sémára csatlakozni.
Előfordulhat, hogy bizonyos adatbázisok esetén nem találunk egyszerű módot (parancsot) séma másolásra.
Ilyenkor a további pontokban kifejtett opcióink maradnak.
2.3.1 Új üres séma létrehozása DB dobás helyett
Ha csak a séma másolás okoz gondot, és nincs szükségünk feltétlenül a másik sémában tárolt adatokra, akkor azért, hogy ne kelljen eldobni az adatbázis sémát, használhatjuk az adatbáziskezelők felületét is új üres séma létrehozására.
Alapvetően, ha követjük a Liquibase oldalon javasolt fejlesztési alapelvet, nevezetesen:
a develop branchre már mergelt changeSeteket nem módosítjuk utólag, akkor csak abban az esetben lesz szükséges új sémát létrehozni, amennyiben korábbi vagy a jelenlegi sémával inkompatibilis verziót szükséges telepíteni a tesztkörnyezetre. (pl.: hotfix verzió visszatesztelése miatt.)
Ahhoz, hogy tetszőleges sémával induljon el az alkalmazás
az /opt/project/infrastructure/.env fájlban kell a módosítsuk a DB_SCHEMA változó értékét az általunk preferált séma nevére.
Fontos, hogy mindig győződjünk meg róla, hogy az adott deploy során a megfelelő séma neve szerepel DB_SCHEMA változóban.
2.3.2 Adatbázis másolása
Amennyiben mindenképp szeretnénk másolni a korábbi séma adatait, megoldás lehet, ha az adott instance-on belül a teljes adatbázist másoljuk le.
Az ehhez szükséges parancsok adatbázisonként változhatnak.
Amennyiben az adatbázis másolást választjuk, akkor ahhoz, hogy a megfelelő adatbázissal/sémával induljon el az alkalmazás, szükséges, hogy az /opt/project/infrastructure/.env fájlban mind a DB_SCHEMA, mind a SPRING_DATASOURCE_URL változók értékét módosítsuk.
Fontos, hogy mindig győződjünk meg róla, hogy az adott deploy során a megfelelő séma neve/adatbázis url szerepeljen a DB_SCHEMA, SPRING_DATASOURCE_URL változókban.
3. Adatbázis futtatása lokálisan
Lokálisan az adatbázist dockerben futtatjuk.
Annak érdekében, hogy a lokális fejlesztői környezethez használt adatbázis sémánkat IT tesztek futtatásakor ne veszítsük el,
az alapértelmezett sémán kívül egy test sémát is célszerű létrehozni az adatbázis docker image indításakor.
A tesztek pedig ezt a sémát használják majd a futásuk során.
Ehhez a docker-compose.yml fájlba a megfelelő konfigurációt hozzá kell adni.
Az alábbi lépések részletezik, hogy az egyes adatbázisoknál, milyen konfiguráció szükséges ehhez.
3.1 PostgreSQL
A SEMI Product alapértelmezetten PostgreSQL adatbázist használ, így amennyiben a projekten is ezt használjuk, nincs teendőnk.
3.2 SQL Server (MSSQL)
SQL Server esetén, az alábbi service konfigurációt kell használnunk a backend projekt infrastructure mappájában található docker-compose.yml fájlban:
db:
container_name: mssql
# platform: linux/amd64 # Csak MacOS (ARM architektúra) esetén szükséges
image: mcr.microsoft.com/mssql/server:2017-latest
restart: always
volumes:
- ./database/mssql/configure-db.sh:/usr/config/configure-db.sh
- ./database/mssql/entrypoint.sh:/usr/config/entrypoint.sh
- ./database/mssql/init.sql:/usr/config/init.sql
entrypoint:
- /usr/config/entrypoint.sh
environment:
SA_PASSWORD: "Password123"
ACCEPT_EULA: "Y"
MSSQL_COLLATION: Hungarian_CI_AS
TZ: Europe/Budapest
ports:
- "1433:1433"
A fenti konfigurációval automatikusan létrejön a test adatbázis is.
Ahhoz, hogy a tesztek futtatása során ezt az adatbázist használja az alkalmazás, a következő konfigurációt kell
elhelyeznünk a backend/backend-service/src/test/resources/application-test.yml fájlban:
spring:
datasource:
url: jdbc:sqlserver://localhost:1433;databaseName=test;trustServerCertificate=true
SQL Server - too many arguments hiba
Amennyiben az SQL Server docker container indulásakor azt tapasztaljuk, hogy a test adatbázis nem jött létre, és a container logjában az alábbi hiba található:
2024-01-22 14:36:32 Sqlcmd: Error: Microsoft ODBC Driver 17 for SQL Server : Login timeout expired.
2024-01-22 14:36:32 Sqlcmd: Error: Microsoft ODBC Driver 17 for SQL Server : TCP Provider: Error code 0x2749.
2024-01-22 14:36:32 Sqlcmd: Error: Microsoft ODBC Driver 17 for SQL Server : A network-related or instance-specific error has occurred while establishing a connection to SQL Server. Server is not found or not accessible. Check if instance name is correct and if SQL Server is configured to allow remote connections. For more information see SQL Server Books Online..
2024-01-22 14:36:33 /usr/config/configure-db.sh: line 19: [: too many arguments
Abban az esetben adjuk ki az alábbi parancsot:
Melynek eredményeképp létre kell jönnie a test adatbázisnak is.
4. Remote adatbázis használata
4.1 SQL Server (MSSQL)
A sesz-db-dev private key és a DB password elérhetősége
A sesz-db-dev privát kulcsával, és a DB jelszóval kapcsolatban érdeklődjünk a Semi csapatnál:
| Név | Email cím | Telefon | Szerepkör |
|---|---|---|---|
| Katona Áron | aron.katona@intuitech.studio | +36203160057 | Projekt Architekt |
| Kazsik Ádám | adam.kazsik@intuitech.studio | +36702900328 | Szenior Fejlesztő |
| Surányi Ákos | akos.suranyi@intuitech.studio | +36203753887 | Szenior Fejlesztő |
Amennyiben szeretnénk használni az SQL Server FILESTREAM fájltárolási módszerét, szükséges lesz egy remote adatbázist létrehozni.
Ehhez már van egy EC2 instance, ahol fut egy Windows Server, amire telepítve van az SQL Server. Ezen a gépen tudunk az alábbi lépéseket követve egy új Database-t létrehozni a projektünkhöz:
- Jelentkezzünk be az AWS Console-ba.
-
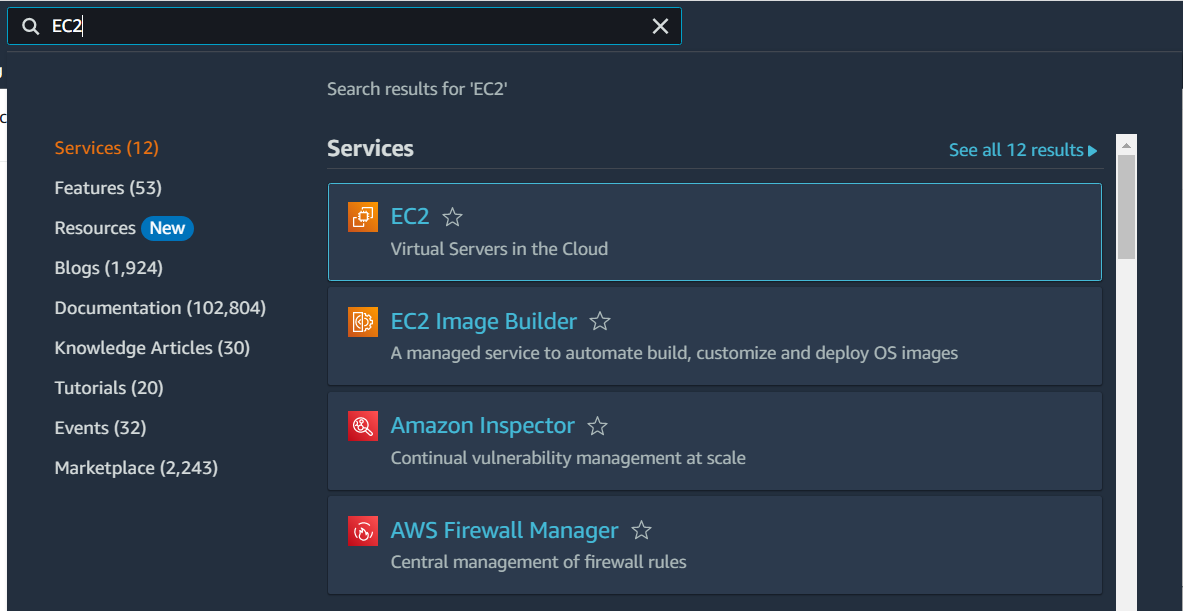
A keresőbe írjuk be hogy „EC2“, majd a megjelenő Services szekcióban válasszuk ki az EC2-t.
-
Győződjünk meg róla, hogy a jobb felső sarokban a Frankfurt régió van kiválasztva.

-
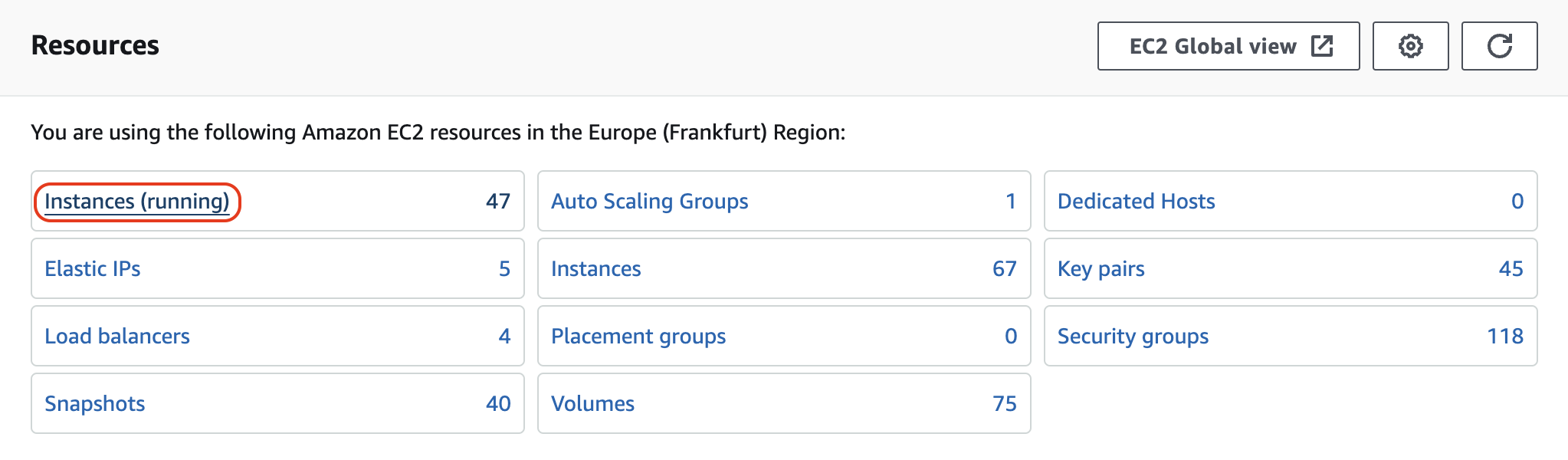
Az EC2 Dashboard-on, a Resources dobozban kattintsunk az Instances(running) linkre.
-
A megnyíló Instances képernyőn a keresőbe írjuk be, hogy
sesz-db-dev, majd az így megjelenősesz-db-devinstance-nál kattintsunk jobb egérgombbal az Instance ID-ra, és válasszuk a Connect opciót.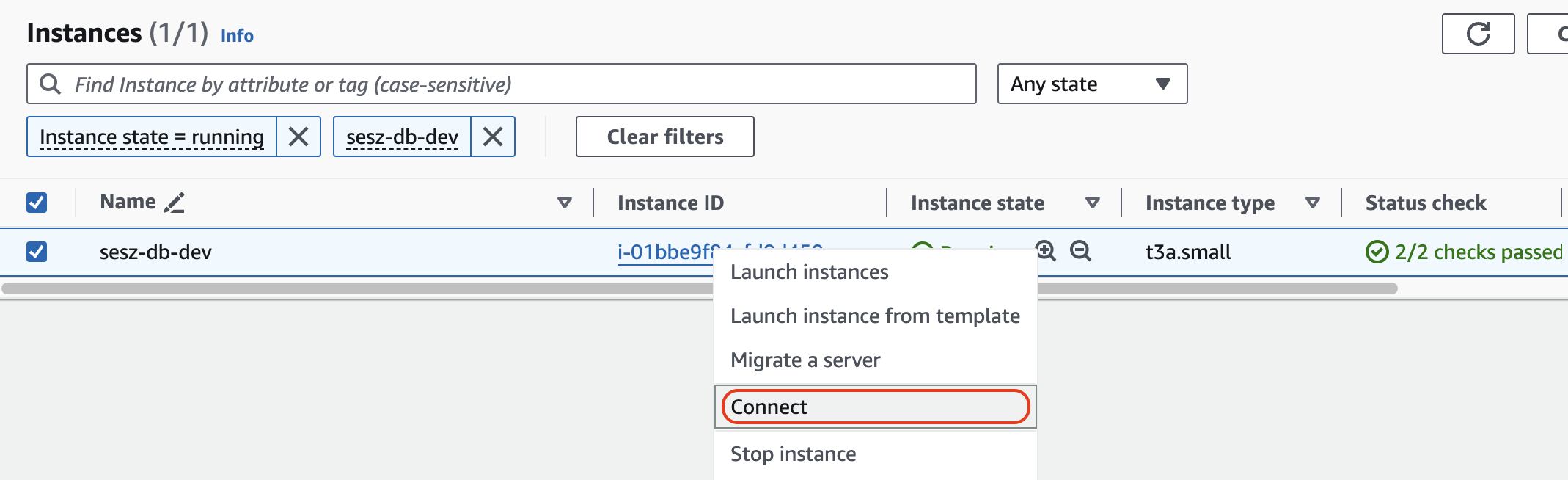
-
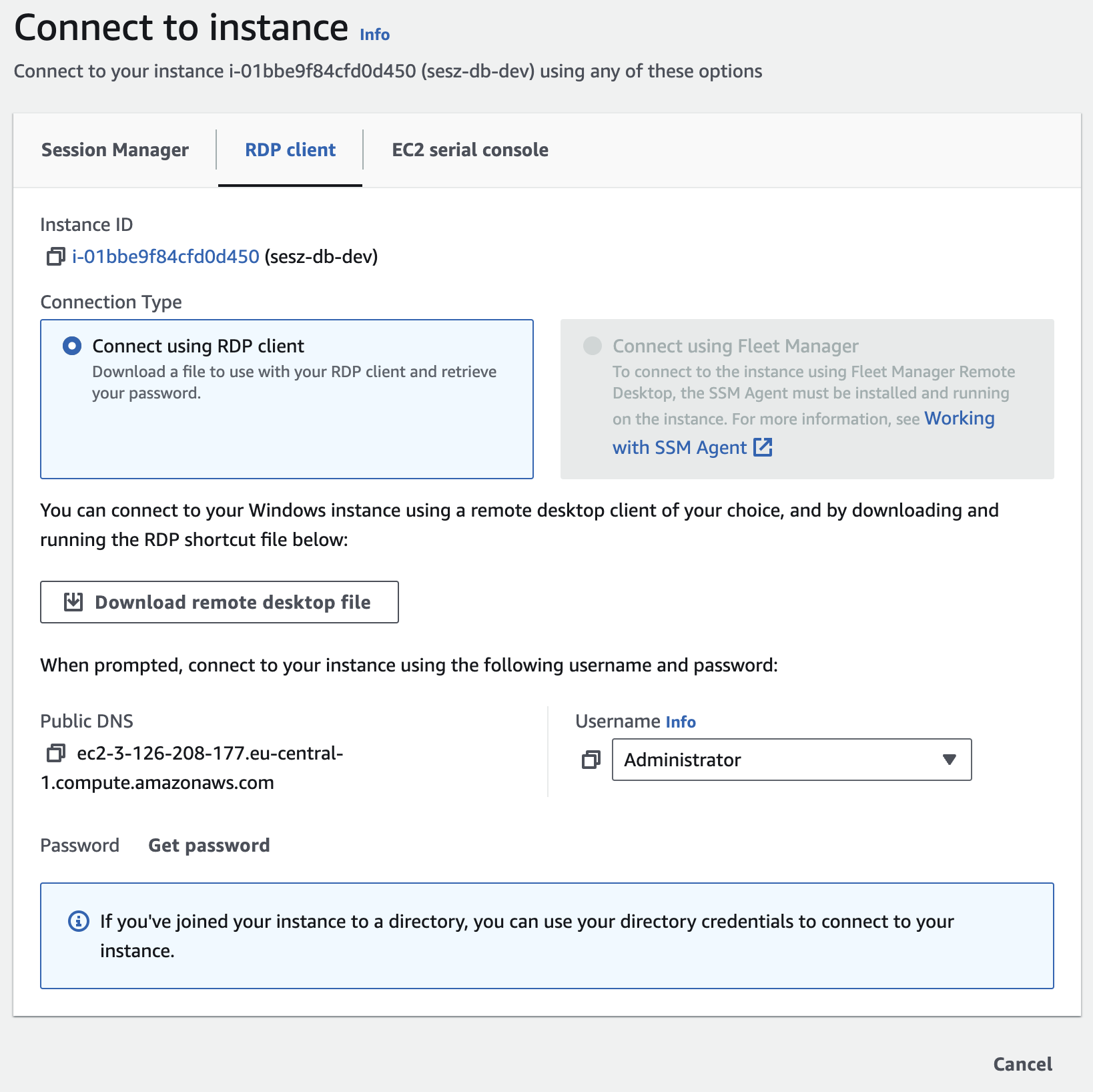
A Connect to instance képernyőn válasszuk az RDP client lapot, majd kattintsunk alul a szürke Get password linkre.
-
A Get Windows password felugró ablakban kattintsunk az Upload private key password gombra, tallózzuk ki
sesz-db-devprivát kulcsát (A privát kulcsért keressük a Semi Csapat-ot), majd kattintsunk a Decrypt password gombra.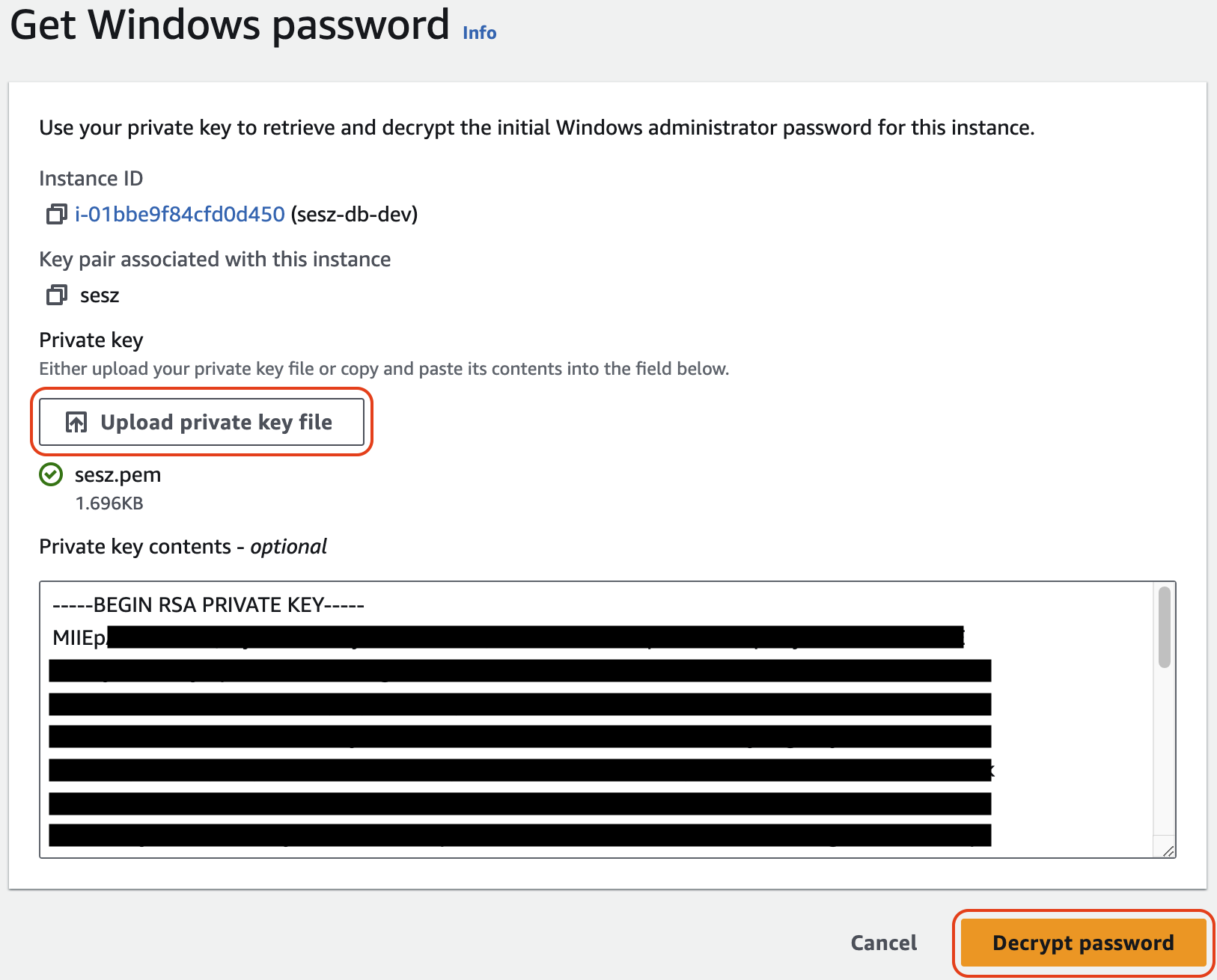
-
Ezt követően a Connect to instance képernyőn alul megjelenik a decryptált jelszó, ezt másoljuk ki, majd kattintsunk a Download remote desktop file gombra.
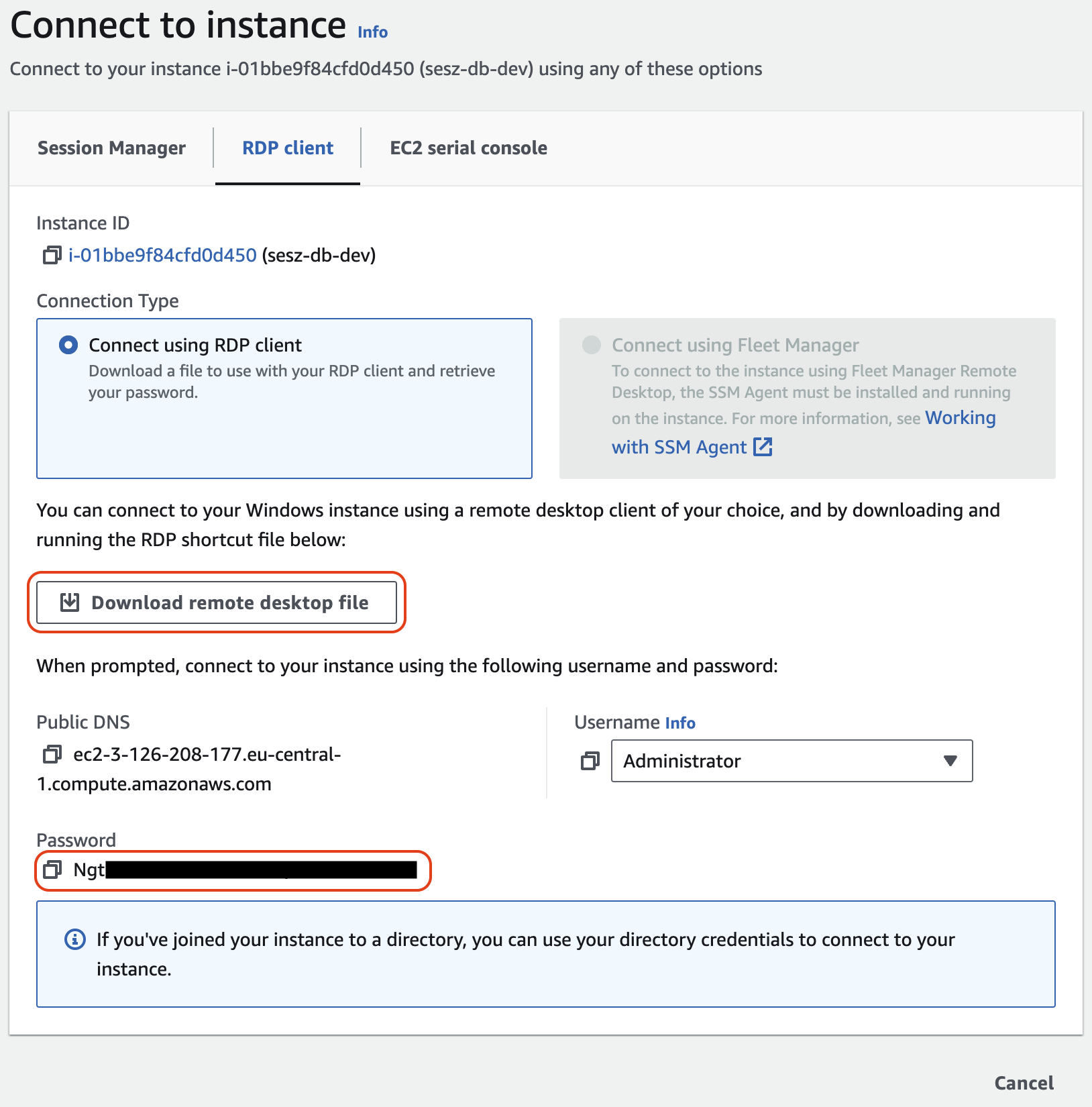
-
Ekkor letöltődik a számítógépünkre a „sesz-db-dev.rdp“ fájl, amit macOS rendszer esetén a Microsoft Remote Desktop alkalmazással tudunk megnyitni.
- Indítsuk el a Microsoft Remote Desktop alkalmazást, és drag ‘n’ drop-oljuk a „sesz-db-dev.rdp“ fájlt a megnyíló ablakba.
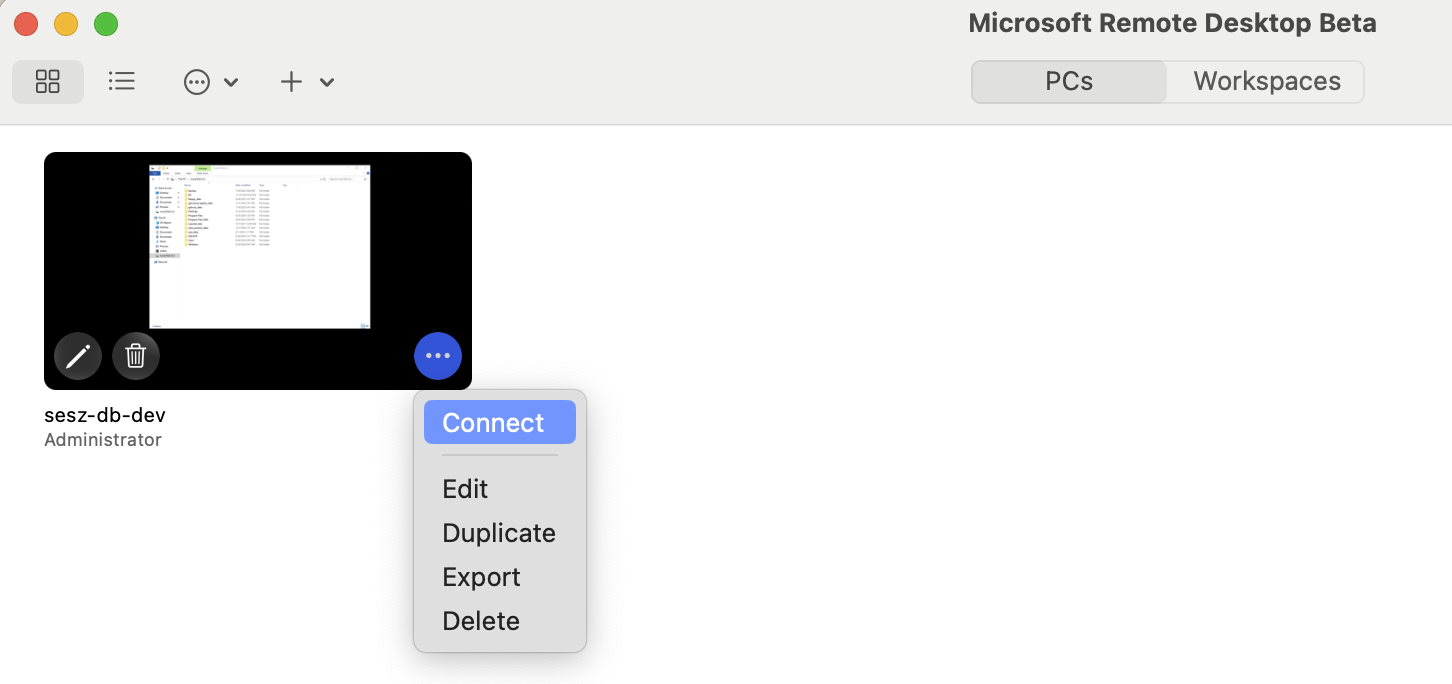
- Ekkor egy téglalap alakú ikon formájában megjelenik a „sesz-db-dev“ mint távoli számítógép.
-
Vigyük az egérmutatót az ikonra, kattintsunk a jobb alsó sarkában a három pötty ikonra, és válasszuk a Connect opciót.
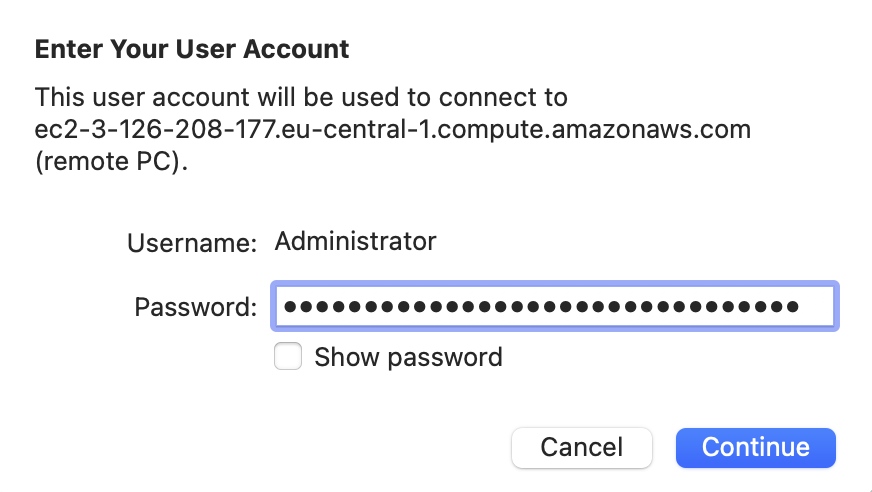
-
A felugró Enter Your User Account képernyőn adjuk meg az AWS Console, Connect to instance képernyőjéről kimásolt jelszót, majd kattintsunk a Continue gombra.
-
Ekkor megjelenik csatlakozást megerősítő képernyő, ahol kattintsunk a Continue gombra.

-
Végezetül megnyílik a
sesz-db-devgép desktop-ja egy ablakban.
-
A
sesz-db-devgépen hozzunk létre aC:meghajtón egy mappát a projektünknek. Ebbe a mappába fognak kerülni a FILESTREAM-ben tárolt fájlok.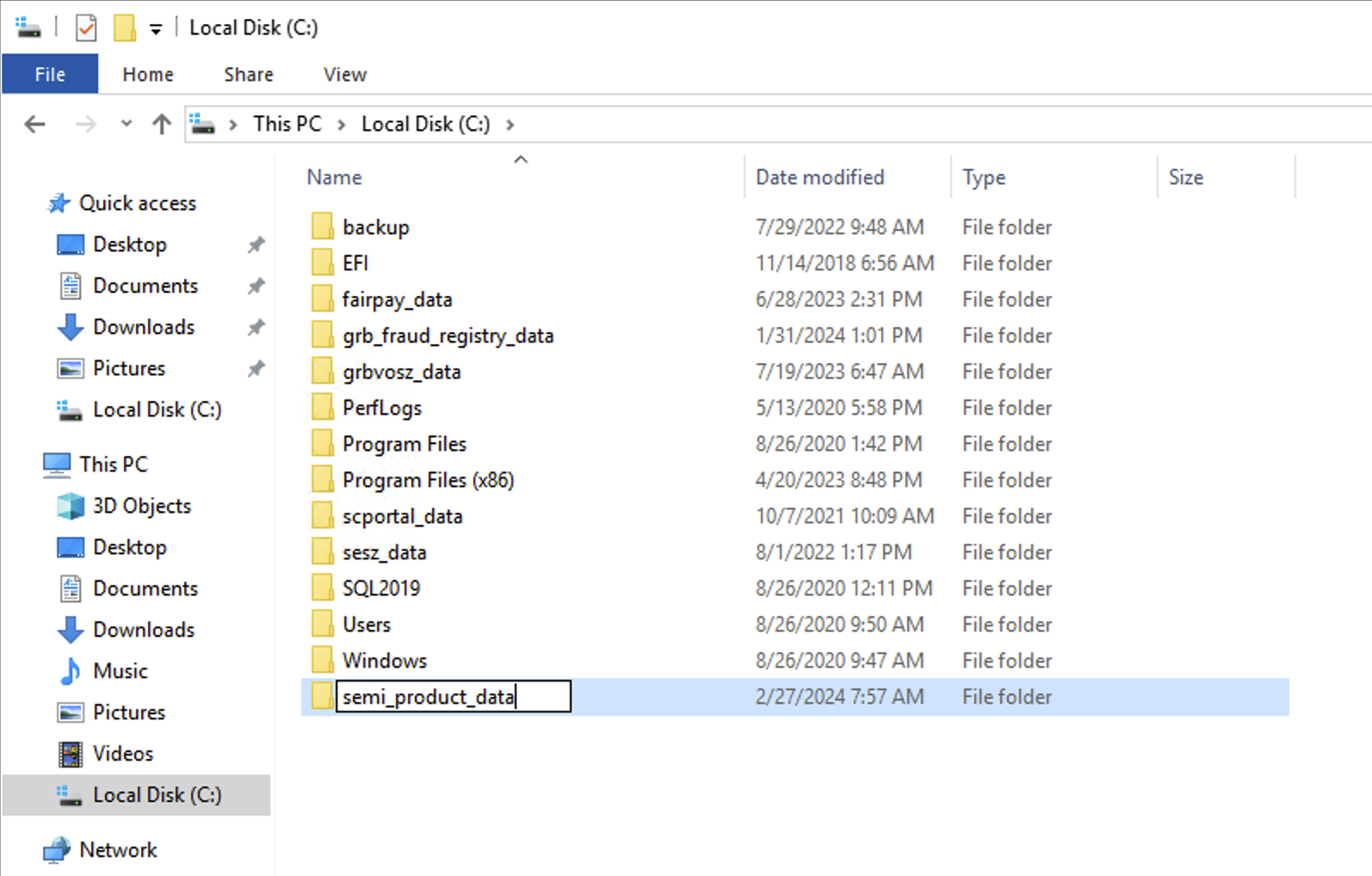
-
Ezt követően bezárhatjuk ezt az ablakot, és lecsatlakozhatunk a
sesz-db-devgépről.
-
IntelliJ-ben csatlakozzunk a
sesz-db-devgépen futó adatbázishoz.-
Adjunk hozzá egy új DataSource-t:
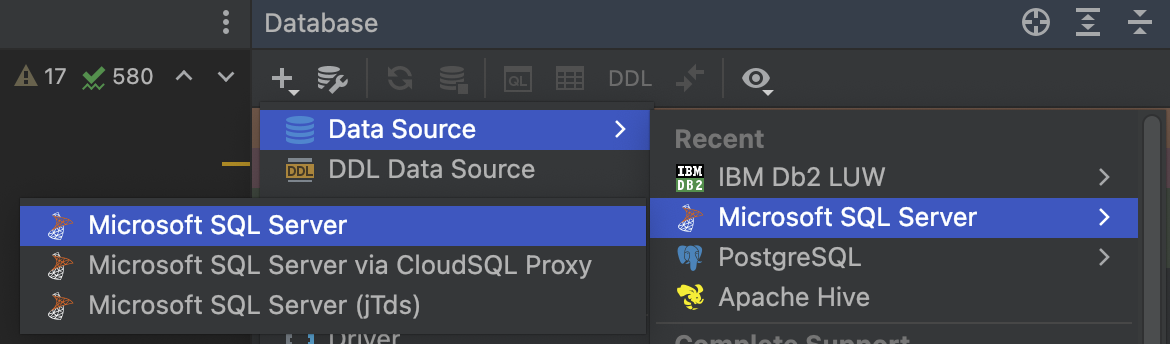
-
A DataSources and Driver képernyőn adjuk meg az alábbiakat:
- Host:
ec2-3-126-208-177.eu-central-1.compute.amazonaws.com - Port:
49172 - User:
sa - Password: Keressük a Semi Csapat-ot.
- Host:
-
-
Nyissunk egy Query Console-t.

-
Hozzuk létre az adatbázist az alábbi scripttel:
CREATE DATABASE [$DB_NAME]; EXEC sp_configure filestream_access_level, 2 RECONFIGURE ALTER DATABASE [$DB_NAME] ADD FILEGROUP $FILE_STREAM_GROUP_NAME CONTAINS FILESTREAM; ALTER DATABASE [$DB_NAME] ADD FILE ( NAME = Uploads, FILENAME = 'c:\$FILESTREAM_FOLDER_NAME\uploads_$DB_NAME') TO FILEGROUP $FILE_STREAM_GROUP_NAME; ALTER DATABASE [$DB_NAME] COLLATE Hungarian_CI_AS;- A
$DB_NAMEplaceholder helyére az adatbázis nevét kell behelyettesíteni. - A
$FILE_STREAM_GROUP_NAMEplaceholder helyére adjunk meg tetszőleges projektspeficikus nevet. Pl.:SemiProductFileStreamGroup. - A
$FILESTREAM_FOLDER_NAMEplaceholder helyére asesz-dev-dbgépen létrehozott mappa nevét kell behelyettesíteni.
Példa a helyesen behelyettesített scriptre
CREATE DATABASE [semi-product-db]; EXEC sp_configure filestream_access_level, 2 RECONFIGURE ALTER DATABASE [semi-product-db] ADD FILEGROUP SemiProductFileStreamGroup CONTAINS FILESTREAM; ALTER DATABASE [semi-product-db] ADD FILE ( NAME = Uploads, FILENAME = 'c:\semi_product_data\uploads_semi-product-db') TO FILEGROUP SemiProductFileStreamGroup; ALTER DATABASE [semi-product-db] COLLATE Hungarian_CI_AS; - A
-
Hozzunk létre dedikált felhasználót:
--Step 1: (create a new user) create LOGIN $DB_USER WITH PASSWORD='$DB_PASSWORD', CHECK_POLICY = OFF; -- Step 2:(deny view to any database) USE master; GO DENY VIEW ANY DATABASE TO $DB_USER; -- step 3 (then authorize the user for that specific database , you have to use the master by doing use master as below) USE master; GO ALTER AUTHORIZATION ON DATABASE::[$DB_NAME] TO $DB_USER; GO- A
$DB_NAMEplaceholder helyére az adatbázis nevét kell behelyettesíteni. - A
$DB_USERplaceholder helyére adjunk meg tetszőleges felhasználónevet. - A
$DB_PASSWORDplaceholder helyére adjunk meg tetszőleges jelszót.
Példa a helyesen behelyettesített scriptre
--Step 1: (create a new user) create LOGIN semiUser WITH PASSWORD='ASdf123456', CHECK_POLICY = OFF; -- Step 2:(deny view to any database) USE master; GO DENY VIEW ANY DATABASE TO semiUser; -- step 3 (then authorize the user for that specific database , you have to use the master by doing use master as below) USE master; GO ALTER AUTHORIZATION ON DATABASE::[semi-product-db] TO semiUser; GO - A
-
Ezt követően IntelliJ-ben, és az alkalmazás konfigurációban, is az előző lépésben létrehozott felhasználóval csatlakozzunk az adatbázishoz.