GenAI Gyorstalpaló

1. Bevezetés 
A gyorstalpaló céljai
A gyorstalpaló célja, hogy a segítségével mindenféle korábbi mesterséges intelligenciával kapcsolatos tudás, alapismeret vagy tapasztalat nélkül bárki el tudjon indulni a GenAI-os fejlesztések újtán.
Nem a mesterséges intelligenciával kapcsolatos mélyreható ismeretek megszerzésére fókuszál, hanem az alapvető fogalmak és gyakorlatok elsajátítására, amelyek segítenek, hogy mielőbb felvedd a fonalat és belevághass a fejlesztésbe.
Ennek érdekében az útmutató lépésről lépésre végigvezet az alábbiakon:
- Alapvető ismeretek megértése: a generatív AI-hoz kapcsolódó legfontosabb fogalmak és technikák
- Előre betanított modellek: előre betanított modellek fajtái, előnyeik és hátrányaik
- OpenAI: OpenAI használatához szükséges lépések és információk
- Prompt engineering: a leggyakoribb technikák és hasznok tippek a prompt engineeringhez
- Hasznos linkek és olvasmányok: bár a leírásban folyamatosan találkozhatsz részletesebb magyarázatot kínáló linkekkel és forrásokkal, a végén egy pontban megtalálod ezeket összefoglalva is
- Gyakorlati példák: a leírás végén találsz egy Jupyter Notebook-ot, amely gyakorlati példákon vezet végig, és amit le tudsz futtatni és ki tudod próbálni, emellett gyakorlófeladatokat is találsz benne
Mi a generatív AI?
A generatív mesterséges intelligencia (GenAI) olyan gépi tanulási technológia, amely új, eredeti tartalmak létrehozására képes különféle médiumokban, például szövegek, képek, zene vagy akár videók formájában.
A GenAI modellek az adatokból tanulva képesek azokat újraértelmezni vagy új formában előállítani. Míg a hagyományos vagy prediktív mesterséges intelligencia főként adatok feldolgozásával, mintafelismeréssel és előrejelzésekkel foglalkozik (például jövőbeli trendek megjóslásával vagy bizonyos események bekövetkezésének valószínűségének előrejelzésével), addig a generatív AI az új tartalmak létrehozására összpontosít.
Mire érdemes használni a generatív AI-t?
A generatív AI sokoldalúan alkalmazható, többféle feladat megoldása során hasznos segítséget nyújthat. Itt találsz néhány használati esetet felsorolva a teljesség igénye nélkül.
- Tartalomgenerálás:
- Szöveggenerálás
- Képgenerálás
- Videógenerálás
- Összefoglalás: Hosszabb szövegek rövid, tartalmas összefoglalóinak elkészítése.
- Szándék és érzelemfelismerés (Intention and sentiment recognition): Az írott vagy beszélt szöveg szándékának és érzelmi töltetének felismerése.
- Struktúrálatlan dokumentumokból adatkinyerés: Segít adatokat kiemelni struktúrálatlan dokumentumokból, megkönnyítve az információgyűjtést.
- Ajánlórendszerek: Személyre szabott ajánlások készítése, például vásárlások vagy tartalomfogyasztás területén.
- Osztályozási feladatok: Adatok kategorizálása előre meghatározott osztályokba.
- Kulcsszókinyerés: Fontos kulcsszavak vagy kifejezések kivonása szövegből.
- Kódgenerálás: Kódírás különböző programozási nyelveken, megkönnyítve a fejlesztők munkáját.
- SQL és egyéb lekérdezések generálása: Adatbázis-lekérdezések automatikus készítése.
Mikor ne válasszuk a GenAI-t?
A GenAI lenyűgöző képességei gyakran csábítóvá teszik a használatát, azonban nem minden probléma megoldására jelentik a legjobb megközelítést. Gyakran érdemes inkább egyszerűbb, hagyományos megoldásokat alkalmazni és a GenAI-t csak akkor, amikor annak erejére valóban szükség van.
Mielőtt egy problémára AI megoldást keresnénk, gondoljuk át és mérlegeljük az alternatív lehetőségeket és azok hatékonyságát. Sok esetben, különösen rutin jellegű vagy kiszámítható feladatoknál, a tradicionális algoritmusok vagy egyszerűbb eszközök épp olyan hatékonyak (vagy hatékonyabbak) lehetnek, de kevesebb erőforrást és kisebb költséget igényelnek.
Random hatjegyű szám generálása GenAI-val és klasszikusan
system_message = f"""
# CONTEXT #
You are a random 6 digit number generator.
# OBJECTIVE #
Generate a 6 digit number.
# RESPONSE #
Just the generated number, nothing else.
"""
messages = [{"role": "system", "content": system_message}]
completion = openai_client.chat.completions.create(
temperature=1.5,
model="gpt-4o",
messages=messages,
)
print(completion.choices[0].message.content)
2. Alapfogalmak 
Nagy nyelvi modellek - Large Language Models (LLMs) 
A nagy nyelvi modellek (large language models, LLM) olyan gépi tanulási modellek, amelyek nagy mennyiségű szöveges adattal való betanítás révén képesek megérteni és generálni a természetes nyelvet. Ezek a modellek képesek kontextusból következtetni, összefüggően és kontextuálisan releváns válaszokat generálni, különböző nyelvekre fordítani, szövegeket összefoglalni, összefüggéseket felismerni, kérdésekre válaszolni és akár kreatív írásban vagy kódgenerálási feladatokban is segíteni.
Ezek a modellek gyakran mély transzformer alapú neurális hálózatok, melyek több milliárd paraméterrel rendelkeznek, mint például a GPT (Generative Pretrained Transformer) modellcsalád tagjai, amit mi is használunk.
Tokenizálás 
A tokenizálás a természetes nyelvfeldolgozás (NLP) egyik alapvető lépése, amely során a szöveget kisebb egységekre, úgynevezett „tokenekre“ bontják. Ezek a tokenek lehetnek szavak, alapszavak, szórészletek vagy akár karakterek. A tokenizálás célja, hogy a nyers szöveget olyan formára alakítsa, amelyet a számítógépek könnyebben tudnak feldolgozni és elemezni. A tokenizálás különösen fontos a szövegfeldolgozás, nyelvi modellezés és gépi fordítás során, ahol a szöveg kezelését alapvetően a tokenek szintjén végzik.
A folyamat során a szöveg vagy egy karakterlánc tokenek listájára bomlik, ahol a tokenek a mondat vagy bekezdés szövegének felelnek meg. Számos algoritmus, mint a transzformerek és más mély tanulási architektúrák, a nyers szöveget token szinten dolgozzák fel. Ahhoz, hogy a modellek hatékonyan végezzék el feladataikat, elengedhetetlen a pontos tokenizálás.
Tipp
Ha szeretnéd vizuálisan is megnézni, hogyan működik a tokenizálás, akkor ezen a weboldalon kipróbálhatod. Kiválóan szemlélteti, hogy néz ki és mekkora egy token, illetve hogyan alakulnak ezek egy szövegben.
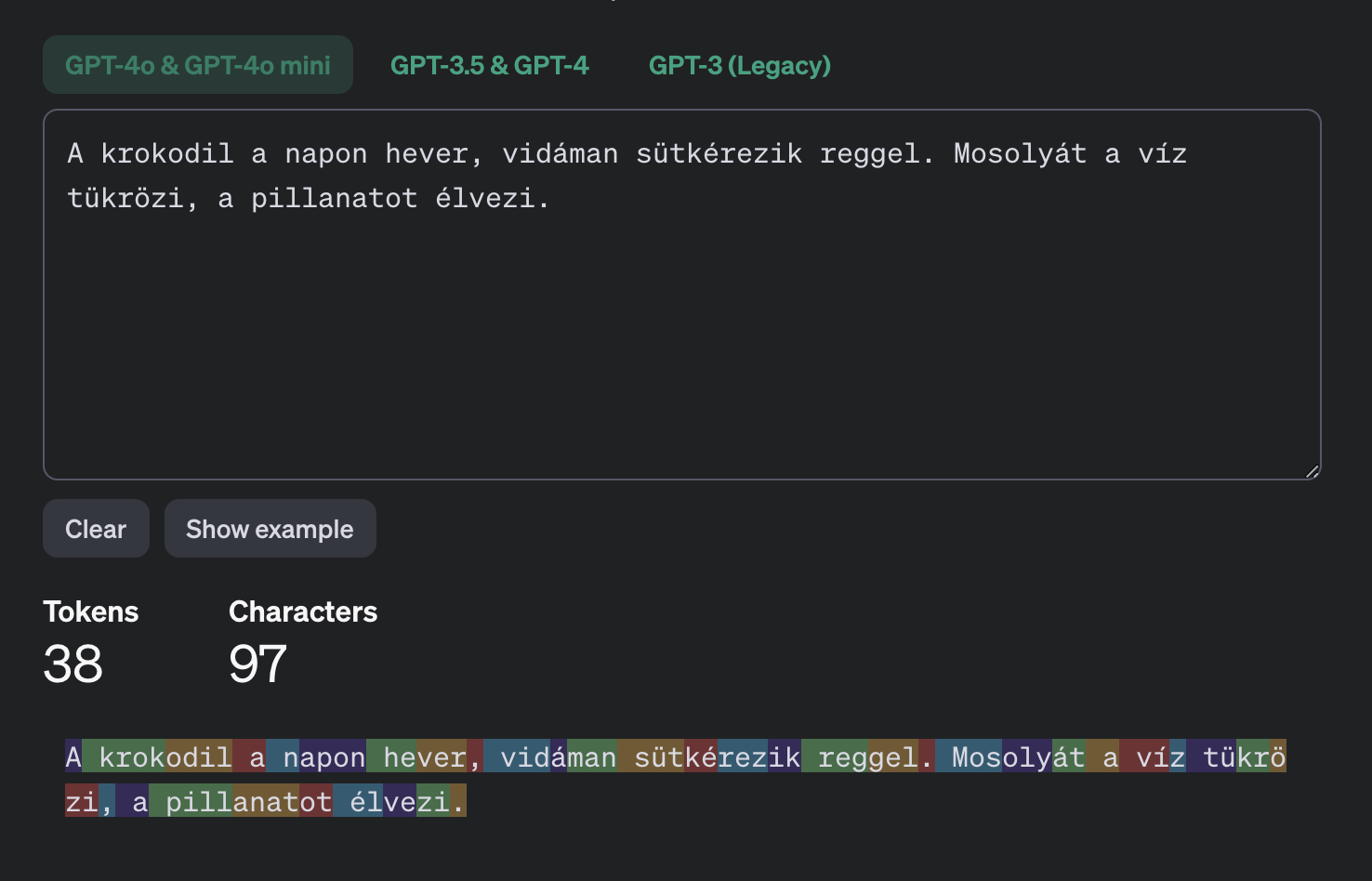
Ha szeretnél erről részletesebben is olvasni, érdemes itt kezdeni.
Prompt engineering 
A prompt engineering azokat a módszereket foglalja magában, amelyek célja a nagy nyelvi modellek (LLM) viselkedésének befolyásolása a kívánt eredmények elérése érdekében, anélkül, hogy a modell súlyain változtatnánk.
Ez egy megfigyelésen és kísérletezésen alapuló technika, melynek során különböző kérdéseket, kijelentéseket vagy utasításokat fogalmazunk meg, amelyeket a modell megért és amelyek alapján az elvárt válaszokat generálja.
Egy egyszerű példa:
Alapmondat: „Az időjárás ma szép, szeretnék kimenni a parkba.“
Prompt: „Írd át a mondatot úgy, mintha a nagyim írná.“
Kimenet: „Drágám, olyan gyönyörű az idő ma, mi lenne, ha kimennénk egy kicsit a parkba? Talán egy kis pikniket is tarthatnánk.“
Prompt: „Írd át a mondatot úgy, mintha egy hivatalos személynek küldeném.“
Kimenet: „Tisztelt XY, a mai időjárási körülmények kedvezőek, ezért fontolóra vettem a parkba történő kimenetelt.“
Prompt: „Írd át a mondatot úgy, mintha a Twitteremre írnám ki.“
Kimenet: „🌞 Szuper idő ma! Kimegyek a parkba. #relax #nature“
Különböző prompt engineering technikák léteznek, erre a témára egy teljes fejezetet szántunk lentebb.
Logit Bias
A prompt engineering mellett egy alternatív módszer a kimenet „igazítására“ az a logit bias-ok szabályozása. Ez finom, kontextuális módosításokra nem igazán alkalmas, helyette általánosan bizonyos kimenetek felé „löki“ a modell által generált szöveget.
A logit bias szabályozásához két paramétert adunk meg, az egyik a token ID, a másik a bias. Ez a pár azt mondja meg a generálási folyamatnak, hogy „bias erősséggel módosítsd a megfelelő token generálási valószínűségét“. Ha például nem szeretnénk, hogy a kimenetünk HTML táblákat tartalmazzon, akkor vegyük a <table> szöveg token ID-ját, és rendeljünk hozzá például -14 bias-t, ezzel azt jelezve a modellnek, hogy a <table> szöveget ne igazán generálja.
Maguk a token ID-k és bias értékek jelentése az modellfüggő. OpenAI modellekhez például itt találunk egy online tokenizer-t, illetve itt pedig a logit bias paraméter leírását. A -100 és 100 értékek itt a teljes tiltást, illetve a biztos generálást jelentik. 100-at természetesen nem érdemes használni, hiszen ekkor a modell csak azt az egy token-t fogja generálni.
A HTML táblázatra vonatkozó példa a GPT-4o modellel például úgy néz ki, hogy a <table tokenhez rendelünk egy negatív bias-t; ennek ID-ja 54505.
Mit reprezentálnak a számok valójában?
A logit bias értékek nem egyenesen a valószínűségekhez adódnak hozzá, hanem a neurális háló kimenetéhez. Ezek az ú.n. logit-ek, melyekből a velószínűségeket a „softmax“ nevezetű függvény készíti el. A softmax függvény feladata, hogy tetszőleges értékekből egy valószínűségi eloszlást hozzon létre, épp ezért a logit bias értékek erőssége nem mindig kiszámítható, főleg kísérletezéssel lehet eldönteni, hogy adott esetben mi a helyes érték.
Retrival Augmented Generation (RAG) 
Egy mélyebbre menő útmutatót itt találsz a RAG-ról.
Retrieval Augmented Generation (RAG) egy olyan technika, amelynek segítségével meglévő adathalmazból származó pontos eredményeket lehet generálni, anélkül, hogy az alapmodellen módosítani kellene. Tegyük fel, hogy olyan kérdésre szeretnénk választ a generatív modellünktől, aminek a megválaszolásához szükséges információn ő nem tanult (pl. saját dokumentum, Gránit Bankos friss információk, vagy bármilyen tartalom, ami az ő feltanítása utáni időszakban keletkezett). Ahelyett, hogy újra kellene tanítanunk egy válaszgenerálásra tökéletesen alkalmas, de tudásában hiányos modellt, odaadhatjuk neki a szükséges információkat, ami alapján már tud válaszolni.
A RAG folyamata két fő komponensből áll: az információ-visszakereső és a generatív modell.
- Bemenet megadása: Egy kérdés vagy kérést adunk meg a rendszer számára, amit a RAG modell fog kezelni.
- Információ visszakeresés: Az első lépésben az információ-visszakereső modell keresést hajt végre a rendelkezésre álló tudásbázisokban, például adatbázisokban, weboldalakon vagy speciális dokumentációkon, annak érdekében, hogy releváns dokumentumokat, információkat találjon a megadott kérdéssel kapcsolatban.
- Generáló modell: A generatív modell, amely gyakran egy nagyméretű nyelvi modell (LLM), a visszakeresett információkat mint kontextus használja fel, hogy koherens és kontextusfüggő választ generáljon a bemeneti kérdésre.
- Kimenet megfogalmazása: Az eredmény egy olyan válasz, amely nemcsak a nyers adatokat foglalja össze, hanem ezeket egyedi, jól összeállított, emberi nyelvhez hasonló mondatokban fogalmazza meg.
Ezzel a RAG lehetővé teszi, hogy az AI rendszer a legfrissebb és legrelevánsabb adatokat használja fel az aktuális válaszok előállításához, anélkül, hogy az alapmodellen módosítana. Ez a megközelítés különösen hasznos, amikor az LLM-ek statikus, előre betanított tudásával ellentétben friss, valós időben gyűjtött információkra van szükség. Lehetővé teszi, hogy a rendszerek gyorsan adaptálódjanak új információkhoz, és releváns, pontos válaszokat adjanak
Embedding és similarity search 
Az embeddingek adott adatok (például szavak, kifejezések, szövegek, képek) vektoros reprezentációi egy numerikus térben, amelyeket gépi tanulási modellekkel hoznak létre, hogy az adatok szemantikai jelentését rögzítsék. Ezek a vektorok olyan tulajdonságok kombinációi, amelyek megőrzik az objektumok közötti fontos kapcsolódási, jelentés- és hasonlósági információkat.
Az embeddingek általában mély tanulási modellekből származnak, ahol a tanulási folyamat során optimalizálják őket, hogy maximalizálják a hasonlóságot a kapcsolódó, és minimálisra csökkentsék a nem kapcsolódó objektumok között.
A similarity search (hasonlósági keresés) az a folyamat, amely során egy adatbázisból keresünk olyan objektumokat, amelyek a leghasonlóbbak egy megadott referenciaponthoz. Ez a keresés az objektumok fent említett vektoros reprezentációját (embeddingjeit) használja a hasonlóság mérésére.
Az embeddingek alapján a hasonlóság mérése különböző távolsági metrikákkal történik, mint például a koszinusz-hasonlóság, euklideszi távolság vagy Manhattan-távolság.
Például, ha azt vizsgáljuk, hogy a „macska“ szóhoz a „kutya“ vagy a „szék“ áll közelebb, a similarity search révén könnyen megállapítható, hogy a „kutya“ vektoros reprezentációja inkább hasonlít a macskáéra, mint a széké. Ez azért van, mert a „macska“ és a „kutya“ egyaránt állatok, míg a „szék“ egy tárgy, így vektoraik a vektoros térben közelebb helyezkednek el egymáshoz a hasonló kontextus miatt.
A Embedding és a Similarity Search együtt egy erőteljes eszköztárat alkot, amely lehetővé teszi a hasonlóságok és kapcsolatok felismerését különféle adathalmazokban, legyenek azok szövegek, képek vagy más típusú adatok.
Vektoros adatok tárolása
Mivel embedding vektorokat használunk hasonlóságalapú keresések végrehajtására, így elengedhetetlenné válik a vektoros adatokat is kezelni képes adatbáziskezelő alkalmazása. Jelenleg mi a PostgreSQL-t, egy nyílt forráskódú adatbázis-kezelőt használunk, mert a pgvector kiterjesztésével az általánosan használt szöveges és numerikus adatok mellett vektoros adatok kezelésére is alkalmas. Ez lehetőséget teremt arra, hogy OpenAI által generált embedding vektorokat tároljunk és lekérdezzünk.
A PostgreSQL előnyei közé tartozik, hogy ingyenes, rugalmas és széleskörűen támogatott, miközben robusztus, megbízható teljesítményt nyújt.
Erről itt találsz részletes leírást és útmutatást a használatához.
Chunking 
A chunking az a folyamat, amikor nagyméretű szövegkorpuszokat kisebb, kezelhetőbb részletekre bontanak. Ez a technika fontos szerepet játszik az LLM-ek hatékony működésében, hiszen lehetővé teszi a nagy mennyiségű adat hatékony feldolgozását és kontextusban tartását.
A RAG technológia alkalmazásánál a felhasználandó adatunkat először chunkokra bontjuk, ezekből képzünk embedding vektorokat és a felhasználó kérdése alapján visszaadott legrelevánsabb chunkokat adjuk oda a generatív modellünknek a kontextusban.
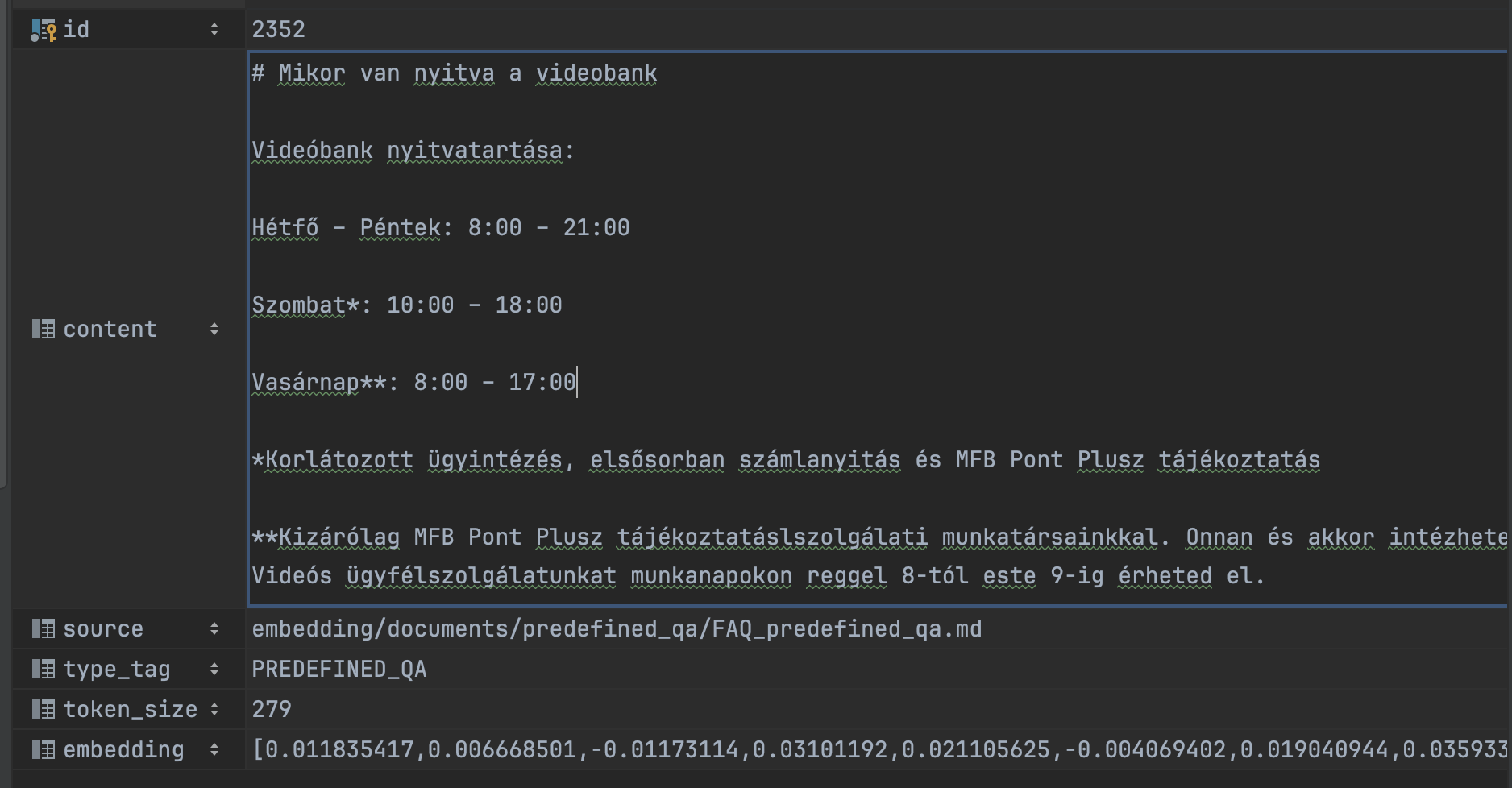
Példa chunk
Például így nézhet ki egy chunk. A képen látható egy rövid, önmagában is értelmes szövegrészlet, hogy hány tokenből áll, valamint a hozzá tartozó embedding eleje.
Hibrid keresés 
A hibrid keresés egy olyan technika, amely több keresési algoritmus kombinálását alkalmazza a keresési eredmények relevanciájának javítása érdekében. Általában a hagyományos kulcsszó-alapú keresés és a modern vektoros, azaz szemantikus keresés ötvözéséről van szó.
A hagyományos kulcsszó-alapú keresés előnye, hogy pontosan tud azonosítani specifikus kifejezéseket, ám érzékeny a helyesírási hibákra és szinonimákra, ami kontextusbeli hiányosságokat eredményezhet. Ezzel szemben a vektoros keresés, amelyet gépi tanulási algoritmusok támogatnak, képes a szövegek szemantikai jelentése alapján keresni, így ellenállóbb a helyesírási hibákkal szemben és jobban kezeli a szinonimákat, azonban érzékeny a kiváló minőségű vektoros ábrázolások jelenlétére, miközben figyelmen kívül hagyhat fontos kulcsszavakat.
A hibrid keresés ezeknek az előnyöknek az összeolvasztásával igyekszik javítani a keresési eredmények relevanciáját, különösen szövegkeresési feladatok esetén. Az eredményeket a hibrid keresés során összefűzéssel és újrasorrendezéssel optimalizálják, így a felhasználók számára a lehető legjobban releváns keresési eredményeket adják vissza.
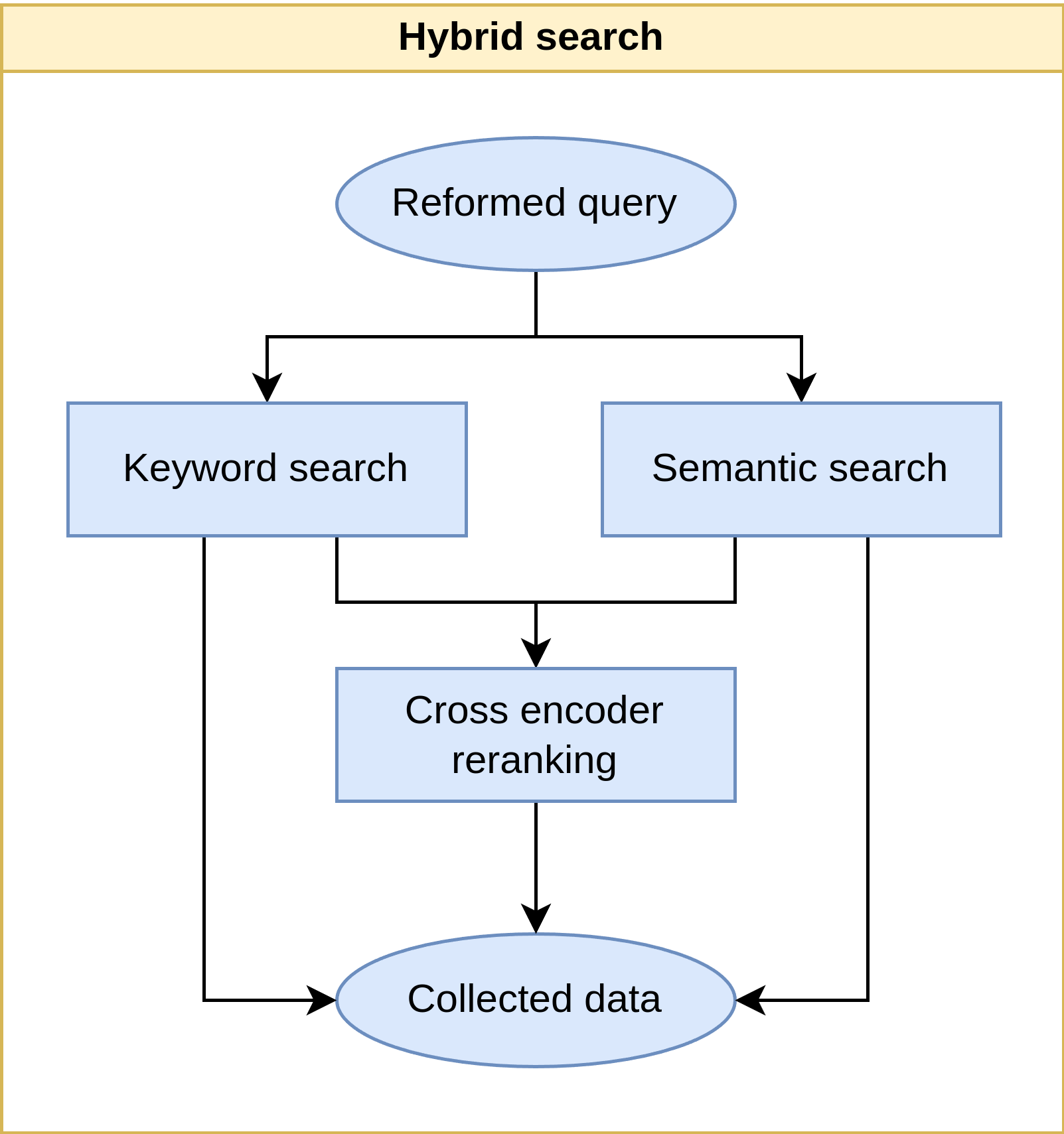
Hibrid keresés a Virtuális Asszisztensben
Jelenleg a mi hibrid keresési folyamatunk így néz ki:
Kontextus (Context)
A kontextus generatív AI és RAG (Retrieval Augmented Generation) rendszerek esetében azt a háttérinformációt vagy kiegészítő adatot jelenti, amely segít az AI modellek számára pontosabb, relevánsabb válaszok generálásában. Lehetővé teszi az AI számára, hogy jobban értelmezze a felhasználói kérdéseket az adott körülmények között, tekintettel a felhasználó szándékaira, a beszélgetés előzményeire, és a rendelkezésre álló adathalmazból összegyűjtött információkra.
A modellek képesek nagy mennyiségű adatot befogadni egy adott kérdés megválaszolására. Ezt a kontextusablak korlátozza, amely meghatározza, hogy mennyi adat használható fel egyetlen kéréshez.
A bemenet és a kimenet esetében is korlátozott a kontextusablak mérete. Például a GPT-4o-mini modellnél a bemeneti kontextusablak legfeljebb 128,000 token befogadására képes, míg a kimenet maximum 16,384 token lehet. Fontos megjegyezni, hogy az LLM minél több kontextust próbál kezelni, annál nagyobb az esélye, hogy elveszik a sok információban vagy kihagy belőle részleteket.
Function call 
A function calling funkció lehetővé teszi, hogy nagy nyelvi modellek (LLMs) dinamikusan hívjanak meg külső vagy belső funkciókat vagy API interfészeket, ezzel bővítve képességeiket a valós idejű adatok lekérdezésére és feldolgozására.
Segítségével a fejlesztők rugalmasabban és hatékonyabban integrálhatják az AI funkcionalitást a rendszereikbe, az ismétlődő vagy összetett feladatok automatizálásával segít optimalizálni a folyamatokat.
Function callokra a gyakorlófeladatoknál látni fogsz gyakorlati példákat is.
Hallucináció 
A generatív AI és nagyméretű nyelvi modellek (LLM-ek) kapcsán a hallucináció arra utal, amikor az AI rendszerek valósághűnek tűnő, de hamis vagy félrevezető információkat generálnak. Ez a jelenség különösen nagy problémát jelent, mivel az ilyen rendszerek gyakran meggyőzően képesek prezentálni a hamis információkat, amelyeket a felhasználók valósnak vélhetnek.
A hallucináció kezelése kritikus fontosságú a generatív AI rendszerek fejlesztésében és alkalmazásában, hogy biztosítsák a felhasználók számára a pontos és megbízható információszolgáltatást.
Finetuning 
A finetuning kifejezés a mesterséges intelligencia, különösen a mélytanulás (deep learning) területén a meglévő modellek további specializálásának és finomhangolásának folyamatát jelenti. A finetuning során egy már előtanított modellt – amelyet már általános adatokon tanítottak – egy specifikus feladatra vagy domainre továbbtanítanak, hogy javítsák a teljesítményét azon a területen.
Ez lehetővé teszi, hogy a meglévő, erős alapokkal rendelkező AI modellek különösen jól teljesítsenek a speciális, sokszor komplex igényeket támasztó alkalmazásokban.
LLM-ek esetén azonban ez elég költséges és időigényes feladat, garantált teljesítményjavulás nélkül.
3. Előre betanított modellek
Egy LLM betanítása rendkívül költséges és erőforrásigényes folyamat, többek között óriási mennyiségű adat, fejlett infrastruktúra, és szakértői tudás szükséges hozzá. Van azonban lehetőségünk előre betanított modelleket alkalmazni saját modell tanítása helyett.
On-premise vs cloud API 

Az on-premise LLM modellek és a cloud API-s modellek közötti fő különbség a telepítés helyében és a hozzáférési módjukban rejlik. Az on-premise modellek a szervezet saját infrastruktúráján futnak, lehetővé téve a teljes kontrollt az adatok kezelésében, miközben nagyobb biztonságot és adatvédelmet kínálnak, viszont jelentős erőforrásbefektetést és karbantartást igényelnek.
Ezzel szemben a cloud API-s modellek a szolgáltatók felhőalapú rendszerein keresztül érhetők el, így könnyebb skálázhatóságot és gyors elérhetőséget biztosítanak, viszont az adatok kezelésében nagyobb mértékben támaszkodunk a szolgáltatók megbízhatóságára és átláthatóságára.
Előnyök és hátrányok
On-premise modellek:
- Előnyök: Teljes kontroll az infrastruktúra és az adatok felett.
- Hátrányok: Magasabb költségek a telepítéshez és karbantartáshoz, nagyobb hardverigény, korlátozott skálázhatóság.
Cloud API-s modellek:
- Előnyök: Gyors telepítés és frissítések, alacsonyabb kezdeti költségek, könnyebb skálázhatóság.
- Hátrányok: Adatvédelmi kockázatok, az adatok feletti kontroll részleges elvesztése, függés a szolgáltatóktól.
Az OpenAI úttörő szerepet játszik az előre betanított nyelvi modellek fejlesztésében és hozzáférhetővé tételében. Az OpenAI által létrehozott GPT (Generative Pre-trained Transformer) modellcsaládot használjuk jelenleg mi is a fejlesztések során. Ezek használatáról a következő fejezetben részletesen olvashatsz majd.
A Hugging Face nevű platform lehetőséget biztosít különféle gépi tanulási (machine learning) modellek on-premise futtatására és a cloud platformokon történő használatra egyaránt, így a felhasználók szabadon választhatnak az igényeiknek megfelelő megoldás között.
Az OpenAI mellett jelenleg még a Hugging Face egy előre betanított CrossEncoder modelljét használjuk.
4. OpenAI használat
OpenAI API kulcs beszerzése
Az OpenAI használatához szükséges lesz saját API kulcsra. Ezt az alábbi módon szerezheted meg:
- Kérj a PA-tól regisztrációs linket!
- Regisztrálj a céges email címeddel!
- Erősítsd meg az email címed és mobil számod!
- Menj az API kulcsokhoz Hozz létre egy titkos kulcsot, és hozz létre egy új kulcsot!
- Mentsd el, mivel később nem lesz elérhető a megtekintésre!
OpenAI modellek
Az OpenAI API változatos modellkészlettel rendelkezik, melyek különböző képességűek és árazásúak.
GPT (Generative Pre-trained Transformer) modellcsalád
A jelenleg elérhető modellek közül
- az egyszerűbb, kisebb feladatokra a
GPT-4.1 mini-t használjuk, ami gyorsabb és olcsóbb, mint a társai - a komplexebb feladatokra pedig a
GPT-4.1-et használjuk
Embedding modellek
A fent kifejtett embedding vektorok létrehozására pedig a jelenleg elérhető embedding modellek közül a text-embedding-3-large modellt használjuk.
Költségek 
Az LLM modellek használatának költsége a bemenő, a kimenő és cachelt bemenő tokenek számától függ, ezek mind külön vannak árazva.
Az embedding modellek költsége pedig a bemenő tokenek számától függ.
Info
Az árazásról részletesebb infókat az OpenAI Pricing oldalán találsz.
Ha megnézed, látszik, hogy az embedding modelleknek jelentősen kisebb a költsége az LLM költségekéhez képest.
API hívás
Egy részletes leírást az OpenAI API hívásáról itt találsz. Itt részletesen kifejtik az egyes megadható paraméterek szerepét és példákat is találsz az egyes API hívás eseteire, például streamelt válaszra, kép bemenetre vagy valószínűségek visszaadására.
Részletesebb magyarázatot pedig a gyakorló példáknál a Jupyter Notebookban fogsz találni.
Nézzük meg most a leggyakrabban használt API hívásokat és paramétereket pár egyszerű példán.
Default API hívás
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
temperature=0,
)
print(completion.choices[0].message)
Ebben a példában beimportáljuk az OpenAI osztályt az openai könyvtárból és létrehozunk egy client objektumot, amit az API-hoz való kapcsolódáshoz fogunk használni.
A client objektumot használjuk, hogy elküldjünk egy chat completion kérést az OpenAI API-nak.
A következő paramétereket adtuk meg:
model="gpt-4o": Ezt a modellt használjuk a válasz generálásához.messages: Ez a lista tartalmazza azokat az üzeneteket, amelyeket a modellhez küldünk. Ebben az esetben tartalmaz egysystemüzenetet, ahol leírást adunk neki a szerepéről, és egy másik üzenetet, ahol a szerepkör (role) „user“, és a tartalom (content) „Hello!“. Tehát imitáljuk, hogy a felhasználó köszönt.temperature=0: Ez a paraméter állítja be a válasz véletlenszerűségét. A 0 érték maximális determinisztikusságot jelent, tehát a modell mindig ugyanazt a legvalószínűbb választ adja. 0 és 2 közt adhatunk meg itt értéket, magasabb értékek pl 0.8 randomabb kimenetet fognak adni, alacsonyabbak pl 0.2 determinisztikusabbat. Úgy is fogalmazhatunk, hogy a modell kreativitását állítjuk itt.
Végül pedig kiírjuk a modell által generált válasz üzenetet. A completion objektum tartalmazza a különböző válasz lehetőségeket (choices), és ebből az első (choices[0]) válasz üzenet (message) tartalmát jelenítjük meg.
Az üzenetek (messages) megadásánál fontos, hogy milyen szerepet (role) állítunk be. Ahogy a példában is látszik, megadhatunk user üzenetet, ami azt reprezentálja, hogy a felhasználótól jött üzenet, de emellett adhatunk meg system, assistant és tool üzeneteket is. Ez segít az LLM számára megérteni, hogy egyes tartalmak kitől érkeztek, és meg tudja különböztetni, hogy rendszerszintű utasítást kapott, vagy a felhasználó írt valamit.
A system üzenetekben adjuk meg a promptunkat. Ebben megadhatjuk, hogy milyen szerepkört várunk az LLMtől, milyen stílust, mi a feladata és tudjuk befolyásolni a viselkedését az elvárt kimenet érdekében.
A promptolási technikákról olvashatsz részletesebben egy későbbi fejezetben.
Function calling
Nézzünk meg egy function callos példát is.
from openai import OpenAI
client = OpenAI()
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
}
]
messages = [{"role": "user", "content": "What's the weather like in Boston today?"}]
completion = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
tool_choice="auto"
)
print(completion)
Ebben a példában létrehozunk egy tools listát, amelynek egyetlen function típusú eleme lesz, aminek a neve get_current_weather.
Megadjuk a function leírását, a tőle elvárt paramétert és annak típusát, valamint választhatóan az unit paramétert, amely „celsius“ vagy „fahrenheit“ lehet. Kikötjük azt is, hogy location paraméter megadása kötelező lesz az LLM számára.
A messages lista most egyetlen felhasználói üzenetet tartalmaz, amelyben az időjárásról kérdez.
Megadjuk a használandó modelt, valamint a tools paramétert, azaz hogy milyen előre definiált eszközökhöz (function-ökhöz) férhet hozzá.
A tool_choice beállítva auto-ra, amely lehetővé teszi a modell számára, hogy automatikusan döntsön az eszköz használatáról.
A function callingról részletesebb magyarázatot kapsz a gyakorlati feladatoknál.
Egyéb lehetőségek
A szöveggenerálás mellett további izgalmas lehetőségek is rendelkezésre állnak, mint például a képgenerálás. Bár ebben az útmutatóban nem térünk ki részletesen ezekre, amennyiben érdekel, itt találsz rá példát és leírást.
5. Prompt engineering 
A prompt engineering az a folyamat, amely során egy nagy nyelvi model (LLM) természetes nyelvű bemeneti utasításait gondosan megtervezzük annak érdekében, hogy a lehető legpontosabb és legrelevánsabb válaszokat kapjuk. A prompt, amelyet a modellnek adunk, meghatározhatja a modell viselkedését, a feladatát, a választott nyelvet, a válasz formátumát és még sok mást is.
Fontos, hogy ez egy megfigyelésen és kísérletezésen alapuló technika, a legmegfelelőbb prompthoz sok iteratív lépésen keresztül lehet eljutni. Ennek során érdemes az éppen aktuális promptot alaposan végigtesztelni és megbizonyosodni róla, hogy az aktuális változtatás még ha meg is oldotta a felmerült problémát, amit szerettél volna, nem rontott-e a modell általános teljesítményén.
Módszerek 
Különböző promptolási módszerek léteznek, érdemes alaposan átgondolni, hogy egy-egy feladatnál melyik lehet a legmegfelelőbb és kísérletezhetünk több módszerrel is, hogy megtaláljuk a leginkább bevált megoldást, vagy akár kombinálhatjuk is őket a még jobb eredmény érdekében.
Ezek közül a legelterjedtebbek:
Zero-Shot Prompting
Ebben az esetben a modell egy rövid és egyértelmű utasítást kap egy feladat elvégzésére, anélkül hogy bármilyen példát szolgáltatnánk. A modell a saját, korábban megszerzett tudáson alapuló válaszokat ad.
Példa: „Kérek pár fun factet a krokodilokról!“ 
A modell önállóan generál néhány fun factet a kérés alapján.
Few-Shot Prompting
Az utasítás mellé adunk néhány példát a modell számára, hogy jobban megértse a feladatot.
Példa: „Írj egy rövid 4 soros verset! Például: ‘Krokodil a napon hever, Vidáman sütkérezik reggel. Mosolyát a víz tükrözi. A pillanatot élvezi.’“
Ezáltal a modell jobban megérti a feladat természetét és stílusát.
Chain of Thought (CoT)
Ez a megközelítés arra ösztönzi a modellt, hogy átgondolja és részletezze megfontolásait a válaszadás során. Ez különösen hasznos lehet összetett problémák esetén.
Példa: „Gondolkodj hangosan: Ha 5 krokodil 10 perc alatt úszik át egy tavon, mennyi időbe telik 2 krokodilnak ugyanezt megtenni? Milyen lépések szükségesek a számítás elvégzéséhez?“
Tree of Thoughts (ToT)
Egy fejlettebb módszer, amely során a modell különböző logikai útvonalakat vizsgálhat, különféle nézőpontokat mérlegelve. Ezt is összetettebb problémáknál érdemes használni.
Példa: „Milyen hatásai lehetnek a klímaváltozásnak a krokodilpopulációkra? Vizsgálj meg több lehetséges forgatókönyvet, beleértve a táplálékhálózatok változásait, az élőhelyek módosulását, és a szaporodási minták megváltozását, és elemezd az egyes forgatókönyvek pozitív és negatív következményeit.“
Text Completion
A modell egy gondolat vagy mondat bevezető részletét kapja, amelyet be kell fejeznie.
Példa: „A krokodilok csillogó szemeikkel figyelik a partot, miközben…“
Instruction-Based Prompting
Specifikus utasításokat adunk a modellnek, hogy végrehajtson egy feladatot.
Példa: „Készíts egy listát, hogy mit eszik egy krokodil egy héten.“
Contextual Prompting
A modell számára kontextust biztosítunk, amely segít a releváns válaszadásban.
Példa: „A könyv, amiről beszélek, egy krokodilcsaládról szól, akik egy új, biztonságos tóhoz vándorolnak…“
Multiple Choice Prompting
A modellnek több lehetőséget adunk, és kérjük, hogy válassza ki a legjobbat.
Példa: „Milyen környezetben élnek legszívesebben a krokodilok? a) Sivatag b) Dzsungel c) Mocsár“
Bias Mitigation
A modell válaszából elimináljuk potenciális torzításokat, hogy az eredmény objektívebb legyen.
Példa: „Írj egy beszámolót a krokodilok viselkedéséről, ügyelve a tudományos objektivitásra.“
COSTAR
A COSTAR prompt engineering egy keretrendszer a prompt-ok hatékony megalkotására a nyelvi modellek számára. A COSTAR rövidítés a következő komponenseket foglalja magában:
- Context: Háttérinformációk megadása, hogy a modell megértse a konkrét szituációt.
- Objective: A feladat egyértelmű meghatározása, ami a modell figyelmét irányítja.
- Style: Az elvárt írásstílus megadása.
- Tone: A kívánt tónus beállítása.
- Audience: A célközönség meghatározása, hogy a modell válasza megfelelően szóljon hozzájuk.
- Response: A válaszkimenet formátumának, például szöveg vagy JSON meghatározása, amivel a modell kimeneti struktúráját szabályozzuk.
Példa: Cikket szeretnénk íratni arról, hogyan vigyázzon az ember egy krokodilos élőhelyen.
Context: Az Egyesült Államok déli részén járunk, ahol gyakoriak a krokodilok a mocsarak környékén.
Objective: Írj egy útmutatót a turisták számára, hogyan viselkedjenek krokodilok közelében.
Style: Laza és közvetlen stílusban.
Tone: Segítőkész és vidám, de informális.
Audience: Családok és túrázók, akik először látogatnak el ilyen területekre.
Response: Szöveges formában add vissza az útmutatót.
Best practices 
- Kezeld úgy az LLMet, mintha egy kisiskolás gyereknek adnál meg utasításokat! Minél hosszabb és komplexebb szabályokat kap, annál kevésbé fogja tudni követni az összeset.
- Gondoskodjunk róla, hogy a prompt világos és pontos legyen!
- Iteráljunk! Ha az első próbálkozás nem eredményes, próbáljuk újra módosított promptokkal!
- Győződjünk meg róla, hogy a prompt pontosan tükrözi a kívánt eredményt.
- Adjunk elegendő kontextust a pontos válasz biztosításához - ahol szükséges.
- Érdemes használni a „you must“ kifejetést, ha valamit mindenképp elvárunk az LLMtől. (pl You must include crocodiles in every prompt example.)
- Törekedjünk rá, hogy ne legyen túl hosszú a prompt, mert a túl sok információ közt elveszhet az LLM és nem biztos, hogy mindent figyelembe fog venni.
- Adjunk példát, ahol tudunk.
- A tagadó utasításokat kevésbé tudja jól kezelni, inkább állításokat használjunk. (pl ahelyett, hogy „Don’t write about anything other than crocodiles!“ inkább „Write only about crocodiles!!“)
- Győzödj meg róla, hogy tényleg jól működik-e a prompt, ne csak egyszer próbáljuk ki a módosított verziót, mivel a modell nem determinisztikus!
- Segít, ha az elején (pl COSTARnál a Context résznél) megadjuk a szerepet, amibe bele kell helyezkednie. (pl. You are a crocodile expert.)
- Adhatunk meg különböző, jól elkülöníthető blokkokat, hogy egyértelműsítsük az LLMnek az egyes információkat, például megmondhatjuk, hogy „A
<CROCODILE INFORMATIONS>alatt találod a szükséges információkat“ és ezután a promptba beleírhatjuk a fontos krokis infókat egy<CROCODILE INFORMATIONS>hasznos krokis infók :)</CROCODILE INFORMATIONS>blokkba. - Mivel ember által alkotott adaton van tanítva, így érdemes szépen beszélni vele. A „kérlek“ és az udvarias nyelv használata a promptokban a modell válaszainak együttműködőbbé és pozitívabbá tételét segíti. Emellett a pénzjutalom említése motiváló lehet játékos vagy versenykörnyezetben, hozzásegítve a modellt, hogy érdekesebb válaszokat generáljon.
- Érdemes a promptot angol nyelven írni. Emellett ha számít, hogy milyen nyelven válaszol, akkor adjuk meg azt is a promptban (pl COSTARnál a Response részben).
- Törekedj rá, úgy mint kódolás esetén is, hogy jól struktúrált és karbantartható legyen a prompt.
- Ha szükséges, hogy az LLM tisztában legyen a jelenlegi dátummal (pl olyan információkat vársz el, hogy „tavaly ilyenkor“ mi volt), akkor érdemes a jelenlegi időt átadni neki.
6. Hasznos források és linkek 
Ebben a fejezetben hasznos forrásokat és linkeket találsz egy-egy témákhoz. Ha valami részletesebben érdekel, mélyebb magyarázatra van szükséged, vagy egyszerűen csak kíváncsi vagy, ajánlott ezek böngészése.
-
 OpenAI-s linkek
OpenAI-s linkek
Jelenleg elérhető modellek
Function calling részletes leírás
Pricing
Developer quickstart
Embeddings
Prompt engineering
Tokens
OpenAI Cookbook examples
-
 Adatkinyerés, feldolgozás és tárolás
Adatkinyerés, feldolgozás és tárolás
Tokenizálás
Különböző chunking módszerek
PostgreSQL as a Vector Database
Hybrid search
Knowledge graphs
Embeddinges adatbázisban való keresés
Átfogó, de könnyen érthető leírás a RAGról
-
Prompt engineering
COSTAR-os cikk
Prompt engineering technikák
-
 LLM aréna
LLM aréna
Itt ki tudsz próbálni és összehasonlítani többféle elérhető modellt
-
Mélyebb AI ismeretek
Transformerek működése
A legtöbb LLM jelenleg transformer alapú. Ez egy részletes leírás a transformerek működéséről, ha mélyebben bele akarsz menni és jobban megérteni a transformer alapú modellek működését, akkor ez jó kiindulási alap lehet.
7. Gyakorló feladatok 
Ahhoz, hogy az eddig megismert fogalmakat és technikákat a gyakorlatban is kipróbálhasd, néhány gyakorlati példa következik.
Először egy interaktív Jupyter Notebook segítségével (iteratívan haladva az egyszerűtől a bonyolultabb példák felé) betekintést kaphatsz a jövőben is hasznos és alkalmazandó technikák működésébe. Ezután pedig a Notebook végén pár önállóan megoldandó, gondolkodtató feladatot találsz, hogy ki tudd próbálni a megszerzett tudásod, mindezt Python nyelven.
Jupyter notebook beüzemelése
A notebookot és a hozzá tartozó requirements.txt fájlt innen tudod letölteni.
A kipróbálásához a következő lépéseket kell végrehajtanod:
1. Conda telepítése
A lokális Python telepítéshez Anacondát használunk.
Letöltés: https://www.anaconda.com/download
2. Python környezet létrehozása és aktiválása condával
Az Anaconda telepítése után egy új Python környezet létrehozásához, amely a 3.12.0-s Python verziót használja, a következő lépéseket kell követned egy terminál ablak segítségével:
- új környezet létrehozásához használd az conda create parancsot
- adj meg egy nevet az új környezetednek (-n python_test)
- add meg a Python verziót (python=3.12.0)
Tehát például:
Miután létrehoztad az új környezetet, aktiválnod kell használat előtt. Ezt a következő paranccsal teheted meg:
Éppen aktív környezet
- Az aktiválás után a prompt előtt megjelenik a környezet neve (pl. (pythonservice)), ami jelzi, hogy most már ebben a környezetben dolgozol.
- Ha a prompt előtt (base) a környezet neve, akkor nem a létrehozott környezetet használjuk.
Python verzió
Ha szeretnéd ellenőrizni, hogy valóban a 3.12.0-s Python verziót használod-e az adott környezetben, futtasd a következő parancsot:
python --version
Ezzel sikeresen létrehoztál és aktiváltál egy új virtuális környezetet Anaconda használatával, amely a Python 3.12.0-s verzióját tartalmazza.
Most már telepítheted a szükséges csomagokat és függőségeket ebben a környezetben a conda install vagy pip install parancsok segítségével, attól függően, hogy a csomag elérhető-e a Conda csomagkezelőn keresztül vagy sem.
3. Jupyter csomag telepítése
Fontos, hogy ezt a létrehozott környezeten belül telepítsd, tehát győződj meg róla, hogy az van aktiválva. Amennyiben nem, aktiváld a conda activate python_test paranccsal.
Ezután a jupyter python package telepítése az alábbi paranccsal lehetséges:
4. Egyéb szükséges csomagok telepítése
A notebook futtatásához szükséges lesz még néhány Pythonos package-re mint például az openai, ezeket megtalálod a már letöltött zip fájlban.
Ezeket pedig (miután meggyőzödtél róla, hogy a megfelelő környezet van aktiválva és a requirements.txt fájl eléréséhez vagy navigálva) az alábbi parancs segítségével tudod telepíteni a terminálból:
5. Jupyter lab elindítása
Mielőtt elindítjuk a Jupyter Labot, győződjünk meg arról, hogy a parancssor (terminál) abba a mappába van navigálva, ahol a notebook fájlokat tároljuk vagy amiből el tudjuk azt érni. A Jupyter ugyanis a jelenlegi könyvtárat tekinti indítási pontnak, és ebből a könyvtárból lesz elérhető az itt elérhető összes notebook fájl.
Tehát például ha a Letöltésekbe mentetted a letöltött notebookot akkor a következő paranccsal navigálj át oda:
Ha már a megfelelő mappában vagyunk, használjuk a következő parancsot a Jupyter indításához:
Ez megnyit egy új internetes böngészőablakot vagy fület, amely a kiválasztott könyvtárban található összes elérhető notebookot megjeleníti.
Ezen a felületen új notebookok létrehozására vagy meglévő notebookok szerkesztésére egyaránt lehetőség van. Keresd meg a letöltött példa notebookodat és nyitsd meg.
Ha a bal oldalon a harmadik kis ikonra kattintasz, megjelenik a Notebookhoz tartozó tartalomjegyzék, ami segíthet az eligazodásban.
6. Jupyter notebook használata
Megnyitás után láthatod, hogy egy-egy cellában kisebb kódrészletek vannak. Minden egyes cellát egyesével le tudsz futtatni és megnézni az eredményét.
A notebook futtatásához a fenti menüből a „Run“ menüben válaszd ki a „Run Selected Cell“ opciót, vagy a Shift+Enter billentyűkombinációval is futtathatsz egy adott cellát.
Új cellát beszúrhatsz a notebookba az A és B gyorsbillentyűk segítségével a kijelölt cella fölé (A) vagy alá (B).
Ahogy haladsz, minden futtatott cella eredménye azonnal látható lesz, és az adatok a memóriában maradnak, így bármikor megvizsgálhatod és elemezheted őket a folyamat közben és után is. Ez lehetőséget ad a mélyebb megértésre és a kísérletezésre anélkül, hogy újra és újra végig kellene futtatnod az egész notebookot.
További leírást és használati segítséget a Notebook elején találsz.
Notebook tartalma
A Jupyter Notebook tartalma elérhető a következő wiki oldalon is. Ezzel lehetőséged van később visszanézni a tartalmat anélkül, hogy újra megnyitnád a teljes notebookot. Azonban, első alkalommal mindenképpen érdemes végigmenni az interaktív notebookon.